[Spring] 상품 검색 엔진 최적화와 검색 성능 개선
![[Spring] 상품 검색 엔진 최적화와 검색 성능 개선](/backend/images/2023-01-21-search-engine-optimization/title.jpg)
서비스에서 검색 기능은 사용자가 원하는 컨텐츠를 쉽게 찾을 수 있게 해주기 때문에 중요한 기능 중 하나이다. 하지만 우리 서비스의 검색 기능의 문제점이 한 두가지가 아니었다. 이 글에서는 기존 검색 기능의 문제와 어떤 과정으로 개선했는지 설명한다.
서비스에서 검색 기능은 사용자가 원하는 컨텐츠를 쉽게 찾을 수 있게 도와주기 때문에 필수적인 기능 중 하나이다. 검색 기능이 원활하게 작동하지 않으면 사용자들은 원하는 컨텐츠를 찾기 어렵고, 결국 다른 서비스로 이탈할 가능성이 높아진다.
서비스에서 기존 검색 기능에 문제점이 많았다. 이 글에서는 서비스 검색 엔진의 문제점을 설명하고, 어떤 과정을 통해 검색 성능을 개선했는지를 설명한다.
1. 문제점
서비스는 처음 설계할 당시 추후 마이크로서비스로 전환을 위해
비즈니스 로직 엔진,리뷰 엔진,검색 엔진로 분리하여 설계되었다. 검색 엔진은 Elastic Search를 사용하지 않고, Spring Boot와 MySQL로 개발되었다.
A. 상품 수 증가에 따른 검색 속도 저하
외부 쇼핑몰을 연동하면서 대량의 상품이 서비스에 입력되자 검색 엔진의 검색 속도가 현저히 느려지는 현상이 발생했다.
원인을 파악 한 결과, 검색 엔진에서 검색된 상품 리스트를 가져온 후 해당 상품들에 대해서 검색 횟수를 1 증가시키는데, 여기서 Index로 지정되지않은 칼럼을 조건으로 Update Query를 사용하여 Full Table Scan이 발생했다.
또한 검색 횟수를 1 증가시킬 때, 검색된 상품 하나하나 Update 요청을 보내어 검색된 상품 수가 많을수록 느려졌다.
B. 한글 검색의 불편함
한글은 다른 언어와 달리 초성, 중성, 종성의 조합으로 하나의 글자가 만들어진다. 한글을 입력 할 때에도 초성, 중성, 종성의 순서로 입력해 한 글자를 완성한다.
이러한 한글의 특성으로 키워드 자동 완성 기능기능을 사용 할 때, 완성되지 않은 글자가 한 글자라도 포함된다면 자동 완성이 표시가 되지 않는 문제가 있다.
예를 들어 사용자가 텀블러를 검색하기 위해 텀까지 입력하면 자동 완성 창에 텀블러를 포함하여 텀이 포함된 키워드가 표시되지만, 다음 글자인 ㅂ을 입력해 텀ㅂ이 입력되면 자동 완성에 아무것도 표시되지 않는다.
2. 개선 방법
검색 엔진을 Elastic Search로 교체하면, 추후 Elastic Search의 기능을 이용해 다양한 검색 기능을 편리하게 구현 할 수 있지만 비용 문제도 있고, 당장 검색 기능의 개선이 필요했기 때문에 기존 검색 엔진을 최대한 개선하는 방안으로 결정했다.
A. 검색 속도 저하 개선
검색 속도가 저하되는 문제의 핵심은 아래와 같다.
- Update 쿼리의 조건절에 Index로 지정된 칼럼이 없음
- 검색 횟수를 증가시키기 위해 검색 결과의 수 만큼 Update 쿼리를 보냄
따라서 아래 코드와 같이 Primary Key인 ID를 이용해 업데이트 대상을 빨리 찾을 수 있게 하고, Where In을 이용해 한 번의 쿼리로 여러 항목을 업데이트 할 수 있게 개선했다.
<update id="UpdateSearchCounts" parameterType="java.util.List">
UPDATE SEARCH_KEYWORD
SET SEARCH_COUNT = (SEARCH_COUNT + 1)
, UPDATED_AT = now()
WHERE ID IN
<choose>
<when test="list != null and list.size != 0">
<foreach collection="list" item="item" separator="," open="(" close=")">
#{item.id}
</foreach>
</when>
<otherwise>
(0)
</otherwise>
</choose>
</update>
B. 한글 검색 편의성 개선
저희 검색엔진은 기본적으로 역 인덱스 방식으로 구현이 되어있기 때문에 키워드를 잘 저장하기만 하면 검색 편의성을 개선 할 수 있다. 이후 설명하는 방법으로 키워드를 저장하여 한글 검색 편의성을 개선하였다.
역 인덱스(Inverted Index)란, 키워드를 통해 본문을 찾는 방식이다. 예를 들면 책의 맨 뒷편에 있는 Index 섹션에서 키워드를 찾아 해당 키워드가 존재하는 페이지를 쉽게 찾을 수 있는 원리와 같다.
1. 키워드 자소 분리 저장
kimkevin 님이 개발한 HangulParser로 키워드 자소 분리 기능을 개발했다. build.gradle에 의존성을 추가하여 쉽게 사용 할 수 있다.
// file: `build.gradle`
repositories {
jcenter()
}
dependencies {
implementation 'com.github.kimkevin:hangulparser:1.0.0'
}
HangulParser는 유용한 라이브러리지만 그대로 사용 할 수는 없었다. 왜냐하면 한글이 아닌 문자를 분리/결합을 시도 할 경우 HangulParserException이 발생하기 때문이다. 사용자가 입력하는 키워드에는 한글이 아닌 문자가 포함 될 수 있으므로 아래와 같이 코드를 작성했다.
// file: `KoreanUtil.java`
/**
* 한글의 자소를 분리합니다.
* 한글이 아닌 문자는 그대로 반환됩니다.
* 예를 들어 `USB 허브`가 입력되는 경우
* `USB ㅎㅓㅂㅡ`를 반환합니다.
*
* @param text 문자열
* @return 입력된 문자열 내 한글의 자소를 분리한 문자열
*/
public String disassemble(String text) {
try {
StringBuilder sb = new StringBuilder();
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
// 한글 유니코드 범위
if (c >= 0xAC00 && c <= 0xD7A3) {
// 한글의 경우 자소를 분리하여 StringBuilder에 추가
HangulParser.disassemble(c).forEach(sb::append);
} else {
// 한글이 아닌 경우 그대로 StringBuilder에 추가
sb.append(c);
}
}
return sb.toString();
} catch (HangulParserException e) {
throw new RuntimeException(e);
}
}
/**
* 한글의 자소를 결합합니다.
* 한글이 아닌 문자는 그대로 반환됩니다.
* 예를 들어 `USB ㅎㅓㅂㅡ`가 입력되는 경우
* `USB 허브`를 반환합니다.
*
* @param text 문자열
* @return 입력된 문자열 내 한글의 자소를 결합한 문자열
*/
public String assemble(String text) {
StringBuilder sb = new StringBuilder();
// 연속된 자모를 저장할 리스트
List<String> jamo = new ArrayList<>();
for (int i = 0; i < text.length(); i++) {
char c = text.charAt(i);
if (
(c >= 0x3131 && c <= 0x314E) || // 자음 범위
(c >= 0x314F && c <= 0x3163) // 모음 범위
) {
// 자모인 경우
jamo.add(String.valueOf(c));
} else {
// 자모가 아닌 경우 jamo 내의 자소를 결합하고, 현재 문자 append
if (jamo.size() > 0) {
try {
sb.append(HangulParser.assemble(jamo));
} catch (HangulParserException e) {
throw new RuntimeException(e);
}
jamo.clear();
}
sb.append(c);
}
}
// 결합 할 jamo가 남아있는 경우 결합
if(jamo.size() > 0) {
try {
sb.append(HangulParser.assemble(jamo));
} catch (HangulParserException e) {
throw new RuntimeException(e);
}
}
return sb.toString();
}
2. 초성 추출
초성 추출 코드는 다음과 같이 직접 작성했다.
// file: `KoreanUtil.java`
private static String[] CHOSUNG = {
"ㄱ", "ㄲ", "ㄴ", "ㄷ", "ㄸ",
"ㄹ", "ㅁ", "ㅂ", "ㅃ", "ㅅ",
"ㅆ", "ㅇ", "ㅈ", "ㅉ", "ㅊ",
"ㅋ", "ㅌ", "ㅍ", "ㅎ"
};
/**
* 한글 초성 추출
* @param original 원본 문자열
* @return 초성
*/
public String extractChosung(String original) {
if (original == null) return null;
StringBuilder chosung = new StringBuilder();
for (int i = 0; i < original.length(); i++) {
//현재 위치의 한글자 추출
char c = original.charAt(i);
String stringLocationInfo = String.valueOf(c);
// 한글일 경우
if (c >= 0xAC00 && c <= 0xD7A3) {
// 음절 시작코드(10진값, 문자) : 0xAC00 (44032 ,'가' )
if (stringLocationInfo.charAt(0) >= 0xAC00) {
int unicode = stringLocationInfo.charAt(0) - 0xAC00;
int index = ((unicode - (unicode % 28)) / 28) / 21;
chosung.append(CHOSUNG[index]);
}
}
}
return chosung.toString();
}
마지막으로 위 코드를 활용하여 다음과 같이 처리해주었다.
- 검색 키워드 저장 요청시 키워드 추출 후
disassemble,extractChosung메소드를 호출하여 저장 - 상품 검색 요청시 검색 키워드를
disassemble하여 쿼리 - 키워드 자동 완성 요청시 검색 키워드를
disassemble하여 쿼리하고, 결과를assemble하여 반환 - 기존 저장된 키워드들
disassemble,extractChosung메소드를 호출해 다시 저장하는 배치 작성
3. 결과
검색 결과는
최대 1000개로 제한되었으며, 아래 테스트는 키워드 테이블 내220,033개의 데이터가 존재 할 때 테스트 한 결과이다.
A. 한글 자동 완성 테스트

자동 완성 테스트 결과 키보드로 자연스럽게 가죽을 하는 경우 입력되는 갖과 가죽의 결과로 가죽과 관련된 자동 완성 결과가 출력 되는 것을 볼 수 있었다.
또한 식의 경우도 시계, 시그니처, 식기 등 다양한 검색 결과를 출력 하는 것을 볼 수 있었다.다
따라서 이전보다 한국어에 대해 자동 완성 기능이 사용자에게 더 도움이 될 것이다.
B. 초성 검색 테스트
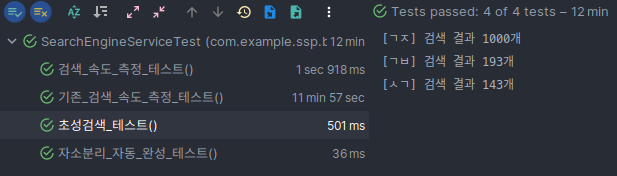
ㄱㅈ, ㄱㅂ, ㅅㄱ로 테스트를 진행하였으며, 검색 결과도 잘 가져 오는 것을 확인 할 수 있었다.
C. 검색 속도 테스트
- 기존 검색 속도
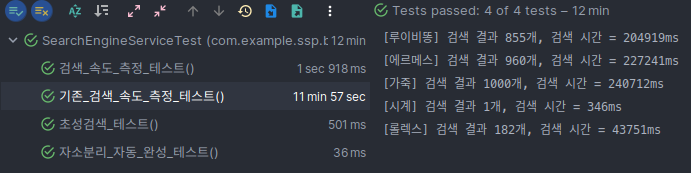
- 개선된 검색 속도
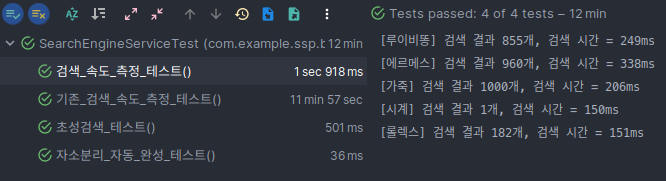
| 키워드 | 검색 결과 수 | 기존 검색 시간 | 개선된 검색 시간 | 성능 개선율 |
|---|---|---|---|---|
| 루이비똥 | 855개 | 204919ms | 249ms | 82196.79% |
| 에르메스 | 960개 | 227241ms | 338ms | 67131.07% |
| 롤렉스 | 182개 | 43751ms | 151ms | 28874.17% |
| 가죽 | 1000개 | 240712ms | 206ms | 116750.49% |
| 시계 | 1개 | 346ms | 150ms | 130.67% |
검색 속도 또한 대폭 개선 되었음을 알 수 있었다. 기존 검색 로직으로는 검색 결과 수가 많을수록 검색 시간이 큰 폭으로 증가했지만, 개선된 검색 로직으로는 검색 결과가 많더라도 검색 시간이 큰 폭으로 증가하지 않았다. 검색 결과가 1개 인 경우에도 약 130% 개선 되었고, 결과의 수가 최대인 1000개인 경우에는 무려 116750% 개선되었다.
성능 개선율은 \(t_1\)을 기존 검색 시간 \(t_2\)를 개선된 검색 시간이라고 했을 때, \(\frac{t_1-t_2}{t_2}\) 공식으로 계산했다.
참고 및 출처
- 타이틀 이미지: Unsplash의Remy Gieling